PIVOT: Iterative Visual Prompting Elicits Actionable Knowledge for VLMs
- Soroush Nasiriany*
- Fei Xia*
- Wenhao Yu*
- Ted Xiao*
- Jacky Liang
- Ishita Dasgupta
- Annie Xie
- Danny Driess
- Ayzaan Wahid
- Zhuo Xu
- Quan Vuong
- Tingnan Zhang
- Tsang-Wei Edward Lee
- Kuang-Huei Lee
- Peng Xu
- Sean Kirmani
- Yuke Zhu
- Andy Zeng
- Karol Hausman
- Nicolas Heess
- Chelsea Finn
- Sergey Levine
- Brian Ichter*
* Equal contribution, ordering randomly decided
PIVOT in Action
Abstract
Vision language models (VLMs) have shown impressive capabilities across a variety of tasks, from logical reasoning to visual understanding. This opens the door to richer interaction with the world, for example robotic control. However, VLMs produce only textual outputs, while robotic control and other spatial tasks require outputting continuous coordinates, actions, or trajectories. How can we enable VLMs to handle such settings without fine-tuning on task-specific data?
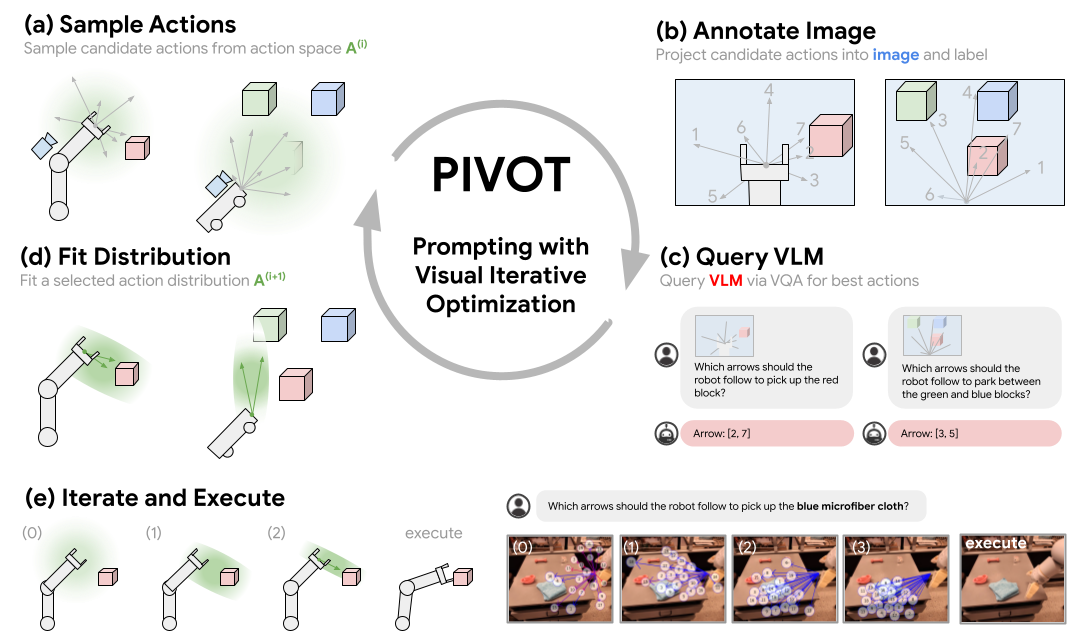
In this paper, we propose a novel visual prompting approach for VLMs that we call Prompting with Iterative Visual Optimization (PIVOT), which casts tasks as iterative visual question answering. In each iteration, the image is annotated with a visual representation of proposals that the VLM can refer to (e.g., candidate robot actions, localizations, or trajectories). The VLM then selects the best ones for the task. These proposals are iteratively refined, allowing the VLM to eventually zero in on the best available answer. We investigate PIVOT on real-world robotic navigation, real-world manipulation from images, instruction following in simulation, and additional spatial inference tasks such as localization.
We find, perhaps surprisingly, that our approach enables zero-shot control of robotic systems without any robot training data, navigation in a variety of environments, and other capabilities. Although current performance is far from perfect, our work highlights potentials and limitations of this new regime and shows a promising approach for Internet-Scale VLMs in robotic and spatial reasoning domains.
Demo
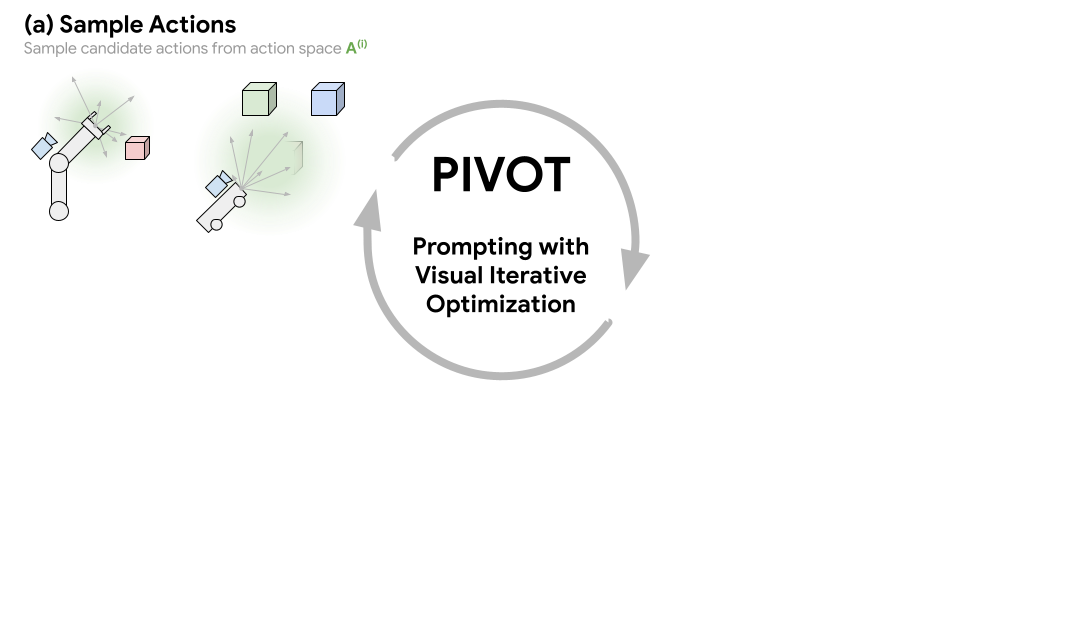
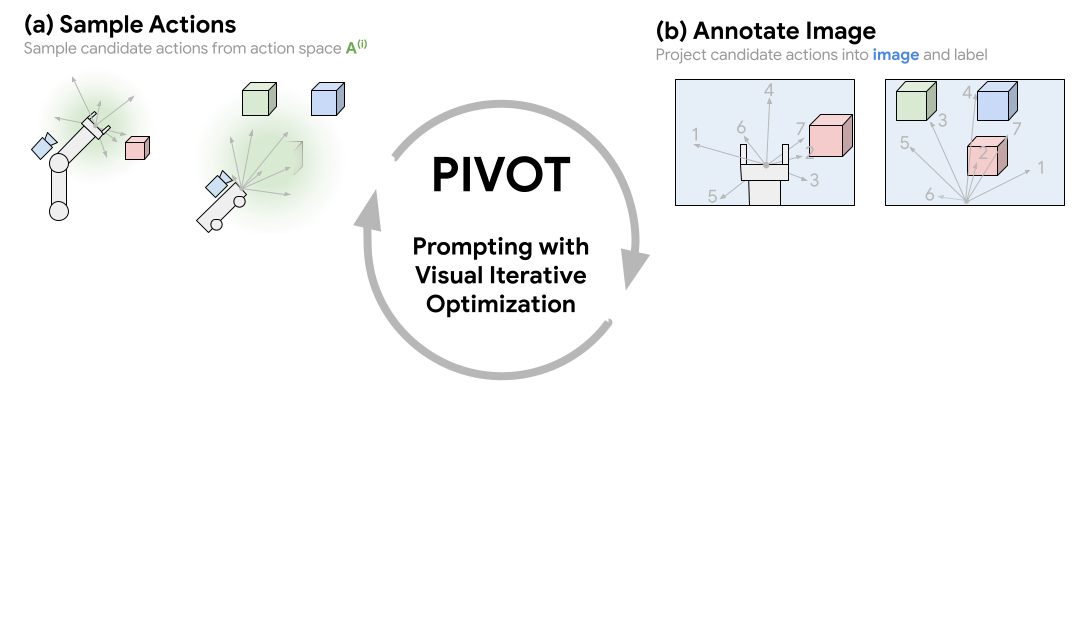
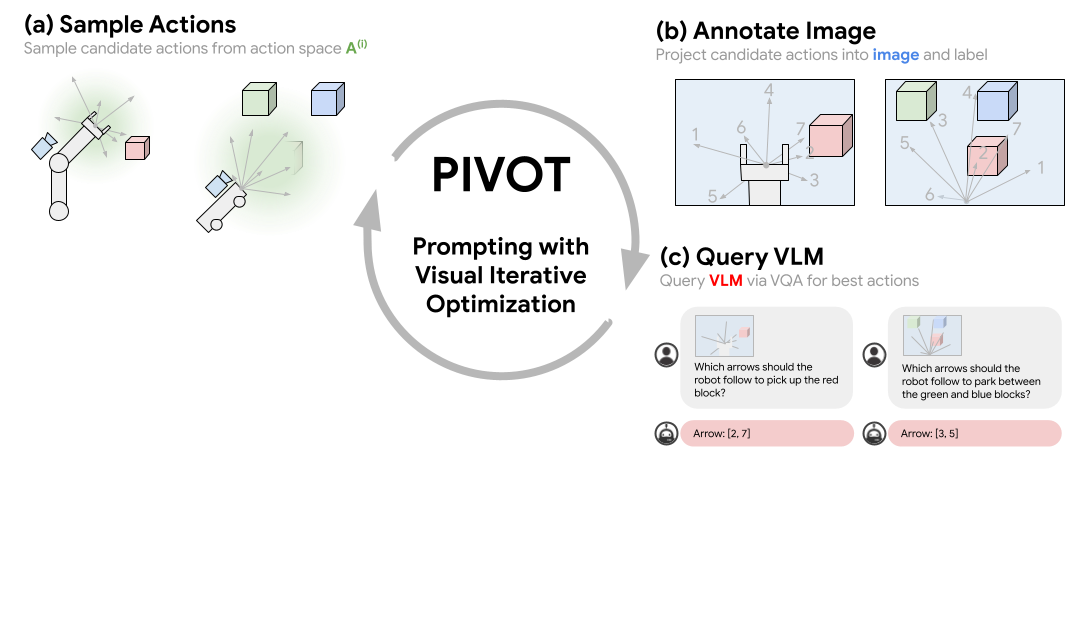
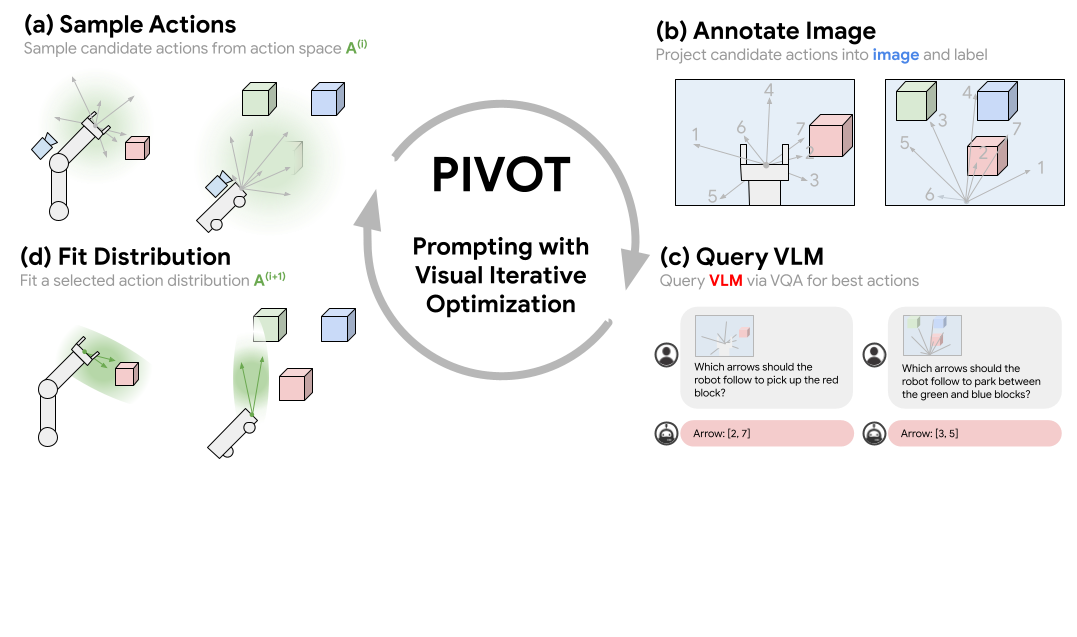
Approach Overview
Prompting with Iterative Visual Optimization (PIVOT) casts spatial reasoning tasks, such as robotic control, as a VQA problem. This is done by first annotating an image with a visual representation of robot actions or 3D coordinates, then querying a VLM to select the most promising annotated actions seen in the image. The best action is iteratively refined by fitting a distribution to the selected actions and requerying the VLM. This procedure enables us to solve complex tasks that require outputting grounded continuous coordinates or robot actions utilizing a VLM without any domain-specific training.

Examples
Examples for inference on ego-centric view videos. The videos are not real-time, and VLM inference calls have been edited out for demonstration purposes.Acknowledgements
We thank Kanishka Rao, Jie Tan, Carolina Parada, James Harrison, Nik Stewart, and Jonathan Tompson for helpful discussions and providing feedback on the paper